Introduction
2025 has been called the year of AI agents. We've moved beyond simple Q&A-style chat interactions to use cases where AI agents handle increasingly complex tasks.
While the importance of "prompt engineering" has been repeatedly emphasized, as AI agents have grown more sophisticated, "context engineering" has emerged as a broader concept that encompasses prompt engineering and has now become mainstream in AI agent development.
For those who are familiar with prompt engineering but only have a vague understanding of context engineering, this article summarizes the concept and importance of context engineering, which will continue to be central to AI agent development.
What is Context Engineering?
Context Engineering became a trending topic following this tweet by AI luminary Andrej Karpathy:
https://x.com/karpathy/status/1937902205765607626
Here, Karpathy points out the importance of context engineering as the art of designing what goes into an LLM's context, beyond just prompt engineering.
For an overview of the elements involved in context engineering, this diagram by Philipp Schmid of Google DeepMind is helpful:
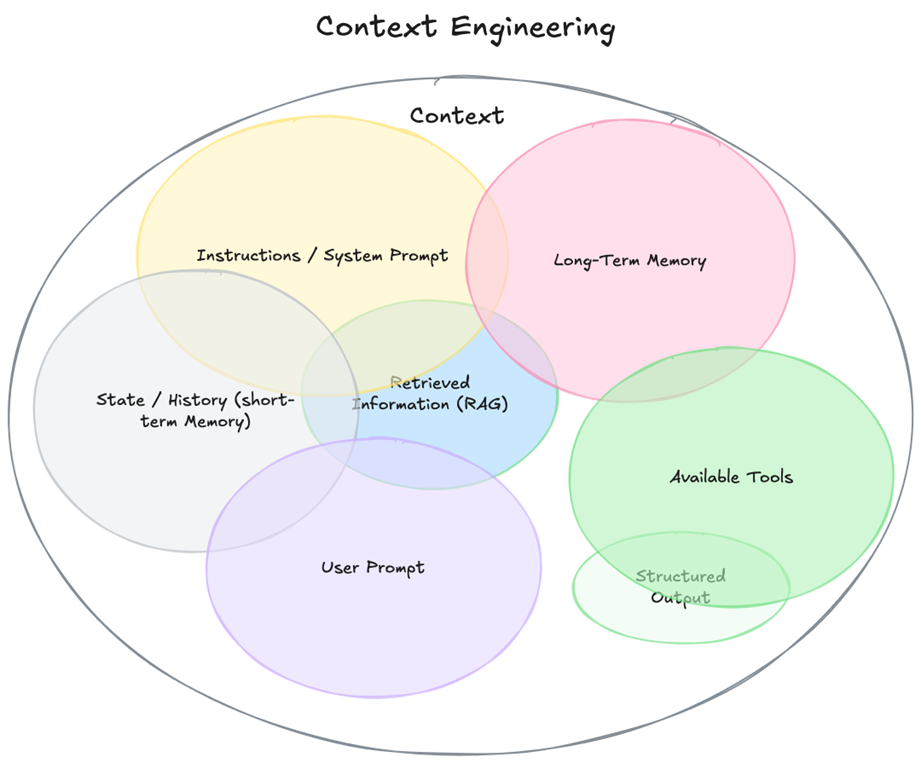
Traditional prompt engineering focused on how to craft system prompts and user prompts. Context engineering is explained as a broader concept that includes prompt engineering plus short-term memory, long-term memory, RAG, tools, and structured outputs.
Context engineering itself is just a concept without a strict definition, and the components and technical approaches discussed within it are constantly evolving.
Therefore, it's better to understand context engineering at a more abstract level to grasp its essential meaning. This will help you understand the whole picture faster and make it easier to catch up with future changes.
When someone who knows nothing about cars tries to learn about them, memorizing each component one by one—the engine, accelerator and brake, steering wheel, wipers—is very inefficient. But if you understand that a car is "something that carries people long distances," you can naturally understand the necessity of the engine for power, the accelerator and brake for driving, and wipers for rainy conditions.
This way, when new things that didn't exist when cars were invented—like navigation systems or child seats—come along, you can naturally catch up by reasoning backward from their necessity.
So what exactly is context engineering? In essence, context engineering is about "creating an environment where AI agents can work effectively." The key point is how to create an environment that maximizes AI's capabilities. Let's think about this more intuitively.
Thinking of AI as a Person
Since discussions about AI tend to get sidetracked, let's think of it in human terms.
Imagine your company has just hired an incredibly talented individual. Their background and skills are impeccable, they're highly motivated, and you secretly think they might be more capable than anyone else in the company. This talented person has become your direct report (let's call them "he" for convenience). He's tremendously capable, but since it's his first day, he naturally knows nothing about the company's internal workings or operations.
How can you get the most out of his abilities?
First, the worst thing a manager can do is "provide no necessary information." Some managers actually do this—thinking "he's talented, so he can figure anything out," they essentially abandon him without explaining anything about the work.
He's talented and motivated, but he has no idea what's expected in this workplace, what he's allowed or not allowed to do, who handles what tasks, or who to ask for help. He becomes utterly confused. Every action becomes like a frame problem, and he can only take the safest, most non-committal actions.
This is a complete waste of talent. But the next problematic case is the opposite: "providing all information."
You explain all organizational information, all internal systems, and give access to every document across all departments. You grant access to all data in internal databases, so there's no information he can't reach.
Does this enable him to perform his work smoothly? It's better than providing no information, but he still can't function well. Why? Because now there are "too many options."
When to ask whom, which system to reference, whether to look at documents or extract from databases—with all these choices, there are too many possible actions, and he becomes paralyzed.
He's probably so talented that he'll try to push forward through trial and error, but since misses far outnumber hits, he'll end up in a research hell of constant backtracking.
Too many options simultaneously increases investigation time and the possibility of rework, so it's not necessarily a comfortable working environment.
So how can he fully demonstrate his exceptional abilities?
First, share the purpose of the work. Who is this work for and why? What level of quality is required? How much time can be spent? What's allowed and what's not? Share the overall picture of the work.
Then share the basic workflow.
The work consists of five major steps. In Step 1, extract basic data from System A and cross-reference with Database B values. In Step 2, conduct research and analysis using System C and Website D. In Step 3, reference past internal documents in Folder D... Explain the workflow overview and which systems and reference materials to use at each stage. Information like "if you're stuck on XX, ask so-and-so" is also very helpful.
Then explain that the final output should be in PowerPoint, using these company design colors, that it's for executives so keep it at a high level of abstraction, and that here's last time's presentation to reference. This dramatically increases clarity about the work.
Of course, since he's talented, you don't need to instruct every single action. Define a reasonable scope, and within that, he'll make what he judges to be the best choices, and ask questions rather than proceeding blindly when unsure.
Even from a subordinate's perspective, compared to a boss who gives no direction or dumps irrelevant information, a boss who provides appropriate information as described above creates a much more comfortable working environment. And this is the essence of context engineering.
In other words, just as it's crucial to provide necessary information at the right time to even a talented human subordinate, context engineering for AI means guiding it to access the right information at the right time and setting up that environment.
With this perspective, the components of context engineering become naturally understandable.
First, the system prompt corresponds to purpose, sharing high-level policy. The user prompt is more specific instruction content.
Short-term memory is naturally needed to remember one's actions and results. Long-term memory functions as a cross-task collection of best practices and knowledge.
RAG provides a mechanism to retrieve relevant information as needed. There are tools to support specific tasks including external information and web searches, and structured output mechanisms to specify the format of final outputs.
Though not mentioned above, sub-agent mechanisms naturally come into play when delegating specific tasks to work as a team.
Since the amount of information an LLM can hold at once (context window size) is limited, it's important to determine what information to provide and when—just like humans have limits on how much information they can process at once.
In essence, the most important aspect of context engineering is not adding information, but "subtracting" it.
Many people hear that "AI agents autonomously select and filter information while performing tasks" and try to provide every piece of information and tool. This additive strategy doesn't work.
When MCP became a hot topic, there was a tendency to promote that connecting all kinds of tools via MCP would make AI agents capable of anything. But this only makes the problems harder for AI to solve and leads to performance degradation.
Just as you would provide a comfortable working environment for a talented subordinate, context engineering—and the key to AI agent development—is not about indiscriminately adding information, but creating an environment where the right information is available at the right time.
By thinking "How can I create an environment where this AI agent can work effectively?" based on your use case, you'll naturally arrive at the necessary technical elements and be able to consider approaches that haven't even emerged yet.
Context Engineering is a Kind of Art
While intuitively understandable, since it's just a concept, there's no clear right answer. There are various best practices, but simply adopting all of them won't guarantee improved AI agent quality.
As Andrej Karpathy pointed out that context engineering is essentially an art, AI agent development is becoming a kind of total artwork by the designer.
When properly considering how business flows should work given AI, the division of roles with humans, what degree of automation to aim for, what the UX for user interactions should be, and so on, it becomes necessary to examine not just the context window but whether to use an LLM at all. These are not independent areas but deeply interrelated domains.
While domain knowledge is naturally required, significant balance and comprehensive skills are demanded as an architect: the design ability to identify where to use AI agents while building the overall flow, internal AI agent design skills, and data engineering skills to organize the reference information itself.
This is one reason why AI agents often stall at PoC stage without reaching production level. Being able to do prompt engineering and AI implementation alone isn't enough—overall design that maximizes AI's potential is critical.
In other words, in the domain of LLM utilization, what's required of AI engineers is creating environments where AI can work.
If you provide the right environment, AI will execute tasks at speeds and quality levels humans cannot achieve. No supercar can drive fast on poorly paved, bumpy roads.
The Pathology of Context
In the article mentioned above, Philipp Schmid of Google DeepMind states that "80% of failures in AI agent development stem from missing context information." Let's dig a bit deeper into why this isn't simply about providing more information.
An important concept called "the pathology of context" is explained with four points in this article:
1. Context Poisoning
This refers to when incorrect information enters the context, that misinformation continues to be referenced in subsequent reasoning, causing the AI agent to take actions different from what was originally intended.
In an experiment where DeepMind's Gemini 2.5 played Pokémon, once an incorrect game state or unachievable goal was included in the context, it would endlessly repeat nonsensical strategies based on that goal.
Context is memory and serves as a guideline for the AI agent, so once incorrect information enters, it's difficult to correct and amplifies over time.
This is somewhat obvious, but when you pass miscellaneous information to an AI agent, if it inadvertently contains substantive errors, the AI agent will act based on that information unless it can logically determine it's clearly wrong.
The quality of information in the context is more important than quantity.
2. Context Distraction
When too much information is crammed into AI at once, even if all of it is relevant, the massive context buries the most crucial instructions, leaving the AI unable to grasp what's important.
As pointed out by "Lost in the Middle," the maximum context length and the length at which practical reasoning is actually possible are different things, so stuffing the context with information is counterproductive.
This is equivalent to piling mountains of related documents in front of a subordinate, making it harder to find the most important information. You need to pass the minimum necessary information.
3. Context Confusion
This phenomenon occurs when irrelevant information or tool definitions are put into the context, causing the model to treat them as meaningful and degrading performance.
In experiments with tool connections via MCP, when only one tool was provided versus multiple tools including unnecessary ones, the latter case showed performance degradation across all models.
What's put in the context is information the model cannot ignore, so it simply adds noise.
Some people try to share everything with subordinates, including irrelevant information, but irrelevant information is just noise that actually dulls judgment and leads to performance degradation.
4. Context Clash
This is when information within the context is contradictory and conflicting.
This requires attention with RAG as well. When documents with poor version control contain both new and old information, the reference information itself is contradictory, preventing the AI agent from making appropriate judgments.
You've probably experienced unorganized internal documents where multiple materials exist for the same content and it's unclear which is authoritative.
If you think providing lots of information is always better and include outdated documents in the AI agent's reference scope, it will retrieve old information too and either fail to make judgments or process whichever information it hits first as authoritative.
When having AI reference data including documents and tools, you need to ensure there are no contradictions in the underlying information.
Conclusion
What did you think?
Being overly influenced by the word "autonomous" in AI agents and dumping numerous pieces of information and tools all at once is, as we've seen, the approach that should be most avoided in AI agent development.
Context engineering, the key to AI agent development, is about providing the right context to AI agents at the right time and setting up conditions for AI agents to reference on their own. This is nothing other than creating an environment where AI agents can work effectively, just like humans.
It's a kind of art, and since it's becoming a domain of total artistry that includes business processes and data organization, it will be where consultants and architects can showcase their skills.
Furthermore, from the business side, having a project manager who gives precise instructions to subordinates and excels at management may lead to building better AI agents.
はじめに
2025年はAIエージェント元年とも言われ、これまでの1問1答的なチャット利用の範囲から、より複雑な業務を任せていくAIエージェントのユースケースが多くなりました。
従来は、いわゆる「プロンプトエンジニアリング」の重要性が繰り返し指摘されていましたが、より複雑なAIエージェントの形となる中で、プロンプトエンジニアリングを含む広範な概念として「コンテキストエンジニアリング」が提唱され、現在はAIエージェント開発におけるメインストリームとなっています。
プロンプトエンジニアリングは知っているが、コンテキストエンジニアリングはざっくりとしか理解していない。。という方に向けて、今回は、今後もAIエージェント開発の肝となっていくコンテキストエンジニアリングのコンセプトと、その重要性についてまとめていきます。
コンテキストエンジニアリングとは
Context Engineeringがトレンドとなったきっかけは、AI界の重鎮である Andrej Karpathy氏による以下のツイートです。
https://x.com/karpathy/status/1937902205765607626
ここでAndrej Karpathy氏は、プロンプトエンジニアリングに留まらず、LLMのコンテキストに何を入れるかを設計する技術としてコンテキストエンジニアリングの重要性を指摘しています。
コンテキストエンジニアリングに含まれる要素の概観を掴むには、Google Deep MindのPhilipp Schmid氏による以下の図がわかりやすいでしょう。
従来のプロンプトエンジニアリングはシステムプロンプトとユーザープロンプトの指示をどう作るかという話でしたが、プロンプトエンジニアリングに加え、短期記憶や長期記憶、RAG、ツール、構造化出力なども含めた広範な概念としてコンテキストエンジニアリングが説明されています。
コンテキストエンジニアリング自体はあくまで概念であるため明確な定義はなく、その中で議論される構成要素や技術的なアプローチも常に移り変わっていきます。
そのため、コンテキストエンジニアリングについては、一段抽象化して本質的な意味を捉えておいたほうが、全体の理解も速くなる上、今後の変化に対するキャッチアップも楽になるでしょう。
車を全く知らない人が車について勉強する時に、車には、エンジン、アクセルとブレーキ、ハンドル、ワイパーがあって・・・と、一つ一つの構成要素を覚えていく事は非常に効率が悪く、車は「人を乗せて遠くまで移動するための物」という事を理解すれば、その動力となるエンジン、運転するためのアクセルとブレーキ、雨が降った時のためのワイパーなどの必要性が自然と理解できるでしょう。
そうすれば、カーナビやチャイルドシートなど、車が発明された当初はなかった新しい物が出てきた時も、その必要性から逆算して自然とキャッチアップできます。
では、コンテキストエンジニアリングとは一体何かというと、コンテキストエンジニアリングとは要するに「AIエージェントが働く環境作り」の事です。ポイントになるのは、AIの能力をいかに最大限引き出す環境を作れるかという事であり、この点をもう少し直感的に理解できるように考えていきましょう。
AIを擬人化して考える
AIの話にすると論点がずれがちになるので、ここでは擬人化して考えてみましょう。
あなたの会社でとてつもなく優秀な人材が採用できたとします。経歴もスキルも文句なしでやる気もある優秀な人材で、おそらく社内の誰よりも優秀なのでは?とあなたも内心思っています。そして、この優秀な人材があなたの直属の部下となりました(ここからは便宜的に彼とします)。彼はとてつもなく優秀ですが、入社初日なので会社内部の事や業務については当然何も知りません。
彼の能力を最大限引き出すにはどうすれば良いでしょうか?
ここでまず、上司の動きとして最悪なケースは「何も必要な情報を渡さない」という事です。実際こういう方もいると思いますが、「優秀だから何でもできるだろう」と思って、業務等について何の説明もなくいわば放置するような形です。
彼は優秀なのでやる気がありますが、そもそもこの職場で何が求められているのか、やって良い事とダメな事は何なのか、誰が何の業務をしていて誰に聞けばいいのかという事がわからず、ただただ困惑してしまいます。一挙手一投足がフレーム問題のようになり、ある種最も当たり障りのない行動しかできなくなるでしょう。
これでは宝の持ち腐れなのですが、次にNGとなるケースは、先ほどとは逆に「あらゆる情報を渡してしまう」という事です。
社内の組織情報、社内のシステムについても全て説明し、他部署も含む社内の全てのドキュメントも参照できるようにしました。社内データベースの全データへのアクセス権も付与したので、ある種彼に手が届かない情報はありません。
ではこれで彼が問題なく業務を遂行できるようになるかというと、何も情報を渡さないよりはまだましですが、これでもまだ上手く動けません。なぜなら今度は逆に「選択肢が多すぎる」からです。
どのタイミングで誰に聞くのが適切なのか、どのシステムを参照すべきなのか、ドキュメントから参照すべきなのかデータベースから抽出すべきなのかなど、あらゆる選択肢の中で、取りうる行動の種類が多すぎるため逆に動けなくなってしまいます。
おそらく彼は非常に優秀なので、試行錯誤しながら何とか前に進もうと頑張ると思いますが、当たりに対して外れの割合が明らかに多いため、ほとんどが手戻りのリサーチ地獄のような形になるでしょう。
選択肢が多すぎるという事は、同時に調査・検討時間の増加と手戻りの可能性を増やす事になるため、必ずしも働きやすい環境とは言えません。
では、彼がその非常に高い能力を存分に発揮するためにはどうすれば良いでしょうか?
まずは、業務の目的を共有します。これはそもそも誰のために実施する何のための業務なのか、品質はどの程度のレベルが求められていて、時間はどの程度かけて良いのか、やってよい事とやってはいけない事などの業務の全体感を共有します。
その上で、業務の基本的なフローを共有します。
業務は大きく5つのステップからなり、ステップ1では、Aシステムからまずは基本データを抽出し、データベースBの値と照合、ステップ2では、このシステムCとウェブサイトDを使って調査・分析を実施、ステップ3では、過去の社内情報をフォルダD内のドキュメントを参照して・・・という形で業務フローの概要とその時々で使うべきシステム、また参考となる情報を説明します。XXで困った時は〇〇さんに聞いてというような情報も非常に助けになるでしょう。
そして、最終アウトプットはパワーポイントで、社内のデザインカラーはこれを利用、役員向けの資料なので抽象度は高めで、前回の資料がこれなのでこれを参照して作成して欲しいとまで指示してあげれば一気に業務の解像度が上がります。
もちろん彼は優秀なので、一挙手一投足のレベルまで指示する必要はありません。ある程度の幅を決めてあげれば、その中で最善と思われる選択を取りながら、わからない所は勝手に進めずに質問もしてくれるでしょう。
自分が部下の立場でも、何も指示されない、または関係ない情報も含めあらゆる情報を渡される上司に比べ、上記のように適切な情報を与えてくれる上司がいる環境は非常に働きやすいと感じるでしょう。そして、これがコンテキストエンジニアリングの本質になります。
つまり、人間の優秀な部下においても、必要な情報を必要なタイミングで適切に渡してあげる事が非常に重要であるのと同様に、AIに対しても、適切な情報を適切なタイミングで利用できるように導いてあげる事、その場を整えてあげる事がコンテキストエンジニアリングになります。
そう考えると、コンテキストエンジニアリングに出てくる構成要素が自然に理解できるようになります。
まず、システムプロンプトは上記の目的にあたり、大上段の方針の共有になります。そして、ユーザープロンプトはもう一歩具体化した指示内容になります。
短期記憶は自分のそれまでの行動や結果を記憶するために当然必要で、長期記憶は業務横断のベストプラクティス・ナレッジ集のような位置付けとして機能します。
必要に応じて関連情報を取得するためにRAGの仕組みがあり、社外情報・Web検索などを含め、特定の作業を支援してくれるツール、そして最終アウトプットがどのような形式なのかという事を指定する構造化出力の仕組みがあります。
上記には出ていませんが、チームとして協業して特定のタスク自体を任せるという事であればサブエージェントの仕組みも当然出てくるでしょう。
このようにLLMが一度に持てる情報(コンテキストウィンドウのサイズ)は限られているので、その中でどのタイミングでどの情報を渡すかという事が重要であり、これは人間が一度に情報処理できる量に限りがあるのと同じ話です。
いわば、コンテキストエンジニアリングで最も重要になるのは、情報の足し算ではなく、情報の「引き算」です。
「AIエージェントは自律的に自分で判断しながら、情報を取捨選択して業務を遂行していく」と聞いてあらゆる情報やツールを渡そうとしてしまうケースが多いのですが、この足し算の戦略は上手くいきません。
MCPがかなり話題になった時も、とにかく色んなツールをMCPで繋げば、AIエージェントが何でもできるようになる喧伝される風潮がありましたが、これはただただAIに解かせる問題を難しくしているだけで、AIのパフォーマンス低下に繋がります。
優秀な部下が働きやすい環境を提供してあげるのと同様に、いたずらに情報を足すのではなく、適切なタイミングで適切な情報が利用できる環境を作ってあげる事がコンテキストエンジニアリングの本質であり、AIエージェント開発の肝になります。
自身のユースケースを踏まえ「どうすればAIエージェントが働きやすい環境が作れるか?」という事を考えれば、自ずとそれぞれの必要な技術要素には辿り着く上に、まだ出ていないアプローチの検討も可能になるでしょう。
コンテキストエンジニアリングはある種のアート
直感的にはわかりやすいですが、あくまで概念であるため何が正解なのかという事はわかりません。ベストプラクティスは色々とありますが、それらを全て採用すればAIエージェントの品質が向上するという単純な話でもありません。
Andrej Karpathy氏がコンテキストエンジニアリングはいわばアートだと指摘しているように、AIエージェント開発は設計者の総合芸術のような形になりつつあります。
そもそもAIを踏まえた上で業務フローはどうするべきか、人間との役割分担、自動化の割合はどの程度を狙うか、ユーザーとのやり取りのUXはどうすべきかなど、正しく検討を進めていけば、コンテキストウィンドウの話だけに留まらず、そもそもLLMで処理すべきかどうかも含めた検討が必要になります。これはそれぞれ独立に進められるものではなく相互に深く関連した領域になります。
業務ドメインの知識も当然必要ながら、AIエージェントの利用箇所を見極めながらフロー全体を組み上げていく設計力、AIエージェントの内部設計力、必要となる参照情報自体も整備するデータエンジニアリングのスキルなど、アーキテクトとしてかなりのバランス感覚と総合力が求められます。
これがAIエージェントがPoC止まりでなかなか実用レベルに至る事が少ない理由の一つです。プロンプトエンジニアリングやAIの実装ができるだけでは不十分で、AIの力を最大限引き出せるような全体設計が重要になります。
つまり、LLMの利用領域においては、AIエンジニアに求められる力はAIが働く環境作りであると言えます。
AIは適切な環境さえ用意してあげれば、人間には出せない速度と品質で業務を遂行してくれます。どんなスーパーカーもボロボロで舗装されていない道路を速く走る事はできません。
コンテキストの病理学
Google DeepMindのPhilipp Schmid氏は、上述の記事の中で、「AIエージェント開発における8割の失敗が文脈情報の欠落に起因する」と述べています。これは単に情報を多く渡せば良いという点ではない事について、少し深掘っておきましょう。
重要な概念として「コンテキストの病理学」という4つのポイントが以下の記事で説明されています。
1. Context Poisoning(コンテキスト汚染)
これは、誤った情報が一度コンテキストに入り込むと、その誤情報が後続の推論で何度も参照され続けてしまい、本来求めていた結果とは異なる行動をAIエージェントが取ってしまうという事です。
DeepMindのGemini 2.5でポケモンをプレイする実験において、間違ったゲーム状態や達成不可能な目標を一度コンテキストに含めてしまうとその目標を前提に意味不明な戦略を延々と繰り返すという事象がおきました。
Context は記憶であり、AIエージェントの指針となるため、一度誤った情報が入ると、誤りが修正されにくく、時間とともに増幅するという課題があります。
これはある種当たり前ですが、雑多な情報をAIエージェントに渡してしまうと、意図せずその中に実質的な誤りが含まれていた場合、AIエージェントは論理的に明らかにおかしいと判断できない限りはその情報を参照して行動してしまいます。
コンテキストに含む情報においては量以上にその質が重要になります。
2. Context Distraction(コンテキスト過多による注意散漫)
AIに一度に多すぎる情報を詰め込むと、たとえそれらの情報がすべて関連していても、膨大なコンテキストが最も核心的な指示を埋もれさせ、AIが重要な点を掴めない状態になります。
いわゆるLost in the Middleで指摘されているように、コンテキスト最大長と実用上まともに推論できる長さは別物になるので、とにかくコンテキストに情報を詰め込めば良いという事ではなくむしろ逆効果になります。
これは、部下の前に大量の関連資料を山積みにすると、むしろ最も重要な情報が見つけられない事と同等であり、なるべく必要な情報を最小限渡す必要があります。
3. Context Confusion(不要情報による混乱)
これはコンテキストに関係ない情報やツール定義を入れすぎるとモデルがそれらを意味があるものとして扱ってしまい性能が低下するという現象の事です。
MCPでのツール接続における実験で、1つのツールだけを渡した場合と、不要なツールも含め複数のツールも渡した場合では、後者の場合、全モデルで性能が低下するという現象が見られました。
コンテキストに入れたものは、モデルにとって無視できない情報であるため、ただただノイズが付加された形になります。
部下に対して、関係のない情報を含めとにかく共有しようとする方が時々いますが、関係のない情報はノイズでしかなく、むしろ情報過多により判断が鈍るため、パフォーマンスの低下に繋がります。
4. Context Clash(コンテキストの衝突)
これはコンテキスト内の情報同士がそもそも矛盾しており、競合しているようなケースです。
RAGなどでも注意が必要ですが、バージョン管理が正しくされていないドキュメントで新しい情報と古い情報を読み取ってしまう場合、そもそもの参照情報自体が矛盾しているため、AIエージェントが適切な判断を下せなくなります。
皆さんも整理されていない社内ドキュメントなどで、同じ内容に対する資料が複数あり、どちらが正なのかよくわからないという経験をした事があるのではないでしょうか。
とにかくたくさん情報を渡した方が良いと考え、既に無効になっているドキュメントもAIエージェントの参照対象にしてしまうと、古い情報も含めて引っ張ってきてしまい、判断自体ができないか、先にヒットした情報を正として処理してしまいます。
ドキュメントやツールを含め、データを参照させる場合は、その先にある情報にそもそも矛盾がないかを担保しておく必要があります。
まとめ
いかがだったでしょうか?
AIエージェントの「自律」という言葉に過度に引っ張られ、多数の情報やツールを一挙に渡してしまう事は、既に見てきたようにAIエージェント開発においては最も避けるべき手段になります。
AIエージェント開発の肝であるコンテキストエンジニアリングは、適切なタイミングで適切なコンテキストをAIエージェントに渡す事、またAIエージェントが自ら参照できる状態を整える事であり、これは人間と同様にAIエージェントが働きやすい環境作りに他なりません。
いわばアートであり、業務プロセスやデータ整備も含むいわば総合芸術のような領域となっていくため、コンサルタント・アーキテクトの腕の見せ所になるでしょう。
更に、業務サイドとしても、部下への指示が的確でマネジメントの上手い方がプロジェクトマネージャーになると、良いAIエージェントの構築に繋がるのではないでしょうか。